Automatic Parallelization
As part of a programming language design class, I worked with another student to develop tools for the automatic "parallelization" of Python code. The overall goal was to develop an easy way to introduce multiprocessing into existing Python code to speed it up without altering its functionality. We came up with three tools, along with a script that converts programs written in pi-calculus to lambda-calculus (don't try to think of how this would ever be useful). The three parallelization tools use the RedBaron library to examine the inputted programs' abstract-syntax trees (ASTs), so to keep with the theme we adopted a similar naming scheme. Each tool is described below.
"Papa Murphy's"
The first tool is a macro system for python written using RedBaron, which does simple non-recursive code transformations based on pattern matching and symbol substitution. It is used in "Digiorno's" (below) to allow the developer to specify how areas of code should be parallelized, but it could be used for any application that required a macro interface (not just for parallelizing your code).
The first tool is a macro system for python written using RedBaron, which does simple non-recursive code transformations based on pattern matching and symbol substitution. It is used in "Digiorno's" (below) to allow the developer to specify how areas of code should be parallelized, but it could be used for any application that required a macro interface (not just for parallelizing your code).
"Digiorno's"
The next tool parallelizes code without requiring the same level of knowledge about multiprocessing as the other tools. It can currently only handle Python's list comprehensions, and will attempt to parallelize any that have "@Parallel" in a comment in the line above them. It does this using macro transformations specified in "Papa Murphy's" and outputs a new Python file that will perform the same as the original.
Because some code cannot be split into multiple processes without changing the functionality, a method is provided to work around this limitation. The programmer is free to add the @Parallel tag to any list comprehension, and when "Digiorno's" is run they can also input a list of command line arguments. The tool then runs the original program with each set or arguments, recording the exit codes and any outputs to the screen. Next it attempts to make the requested improvements, identifying the largest set of changes that can be made that both improve on the original times and do not result in any changes from the original code with any set of arguments.
An example of this process is included below.
The next tool parallelizes code without requiring the same level of knowledge about multiprocessing as the other tools. It can currently only handle Python's list comprehensions, and will attempt to parallelize any that have "@Parallel" in a comment in the line above them. It does this using macro transformations specified in "Papa Murphy's" and outputs a new Python file that will perform the same as the original.
Because some code cannot be split into multiple processes without changing the functionality, a method is provided to work around this limitation. The programmer is free to add the @Parallel tag to any list comprehension, and when "Digiorno's" is run they can also input a list of command line arguments. The tool then runs the original program with each set or arguments, recording the exit codes and any outputs to the screen. Next it attempts to make the requested improvements, identifying the largest set of changes that can be made that both improve on the original times and do not result in any changes from the original code with any set of arguments.
An example of this process is included below.
Here is an simple python script (p3.py in the repo) that uses list comprehensions to pull down the data from a bunch of Wikipedia pages, then performs some operations on them.
Original Python Code (p3.py)
The tool can be used to alter this file like this:
python3 digiornos.py p3.py "-q" ""
This asks the tool to parallelize p3.py wherever "@Parallel" is present in the file, while making sure the exit codes and command line outputs don't change when run with the two provided strings of arguments.
Sample command line output for this execution might look like this:
python3 digiornos.py p3.py "-q" ""
This asks the tool to parallelize p3.py wherever "@Parallel" is present in the file, while making sure the exit codes and command line outputs don't change when run with the two provided strings of arguments.
Sample command line output for this execution might look like this:
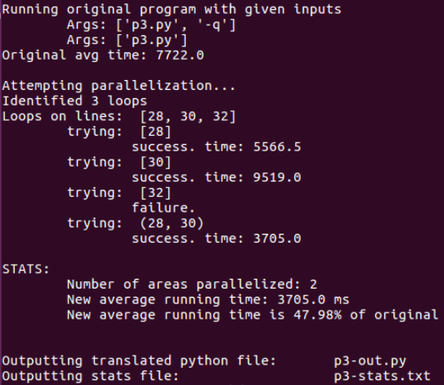
The script creates two files, one containing the new Python code and one repeating the statistics about the parallelization that were also printed to the command line. The new file is included below; notice that the third list comprehension was not changed because altering it would change the value of "X" from the original code.
"Breadsticks"
The third tool is similar to the others but different enough to not merit a pizza name. Rather than list comprehensions, "Breadsticks" targets function calls. It effectively implements a lazy-interpreter, performing the evaluation of parameters to a function call in multiple threads. The called function is changed to take in strings representing the names of these processes rather than the values themselves, and waits for the process to finish before using the variable. This is useful when the result of one function call is passed as an argument to another, and the corresponding variable is not immediately used in the called function.
It should be noted that there are some hygiene issues; attempting to parallelize multiple calls to the same function will not work because the function will be duplicated multiple times, causing naming conflicts. This could be improved upon in the future.
An example of this process is included below.
The third tool is similar to the others but different enough to not merit a pizza name. Rather than list comprehensions, "Breadsticks" targets function calls. It effectively implements a lazy-interpreter, performing the evaluation of parameters to a function call in multiple threads. The called function is changed to take in strings representing the names of these processes rather than the values themselves, and waits for the process to finish before using the variable. This is useful when the result of one function call is passed as an argument to another, and the corresponding variable is not immediately used in the called function.
It should be noted that there are some hygiene issues; attempting to parallelize multiple calls to the same function will not work because the function will be duplicated multiple times, causing naming conflicts. This could be improved upon in the future.
An example of this process is included below.
Here's an example program that we would like to parallelize (fP1.py in the repo). It calls a function called "compare" that pulls some pages from Wikipedia and compares them to other pages that were passed in as function calls.
The code the tool outputs is shown below. Notice that the call to compare has been changed, small functions have been created for each parameter, and a new version of the compare function has been included that allows for the two calls to "urlopen" to be processed while the first part of "compare" is being run. This speeds up the overall execution of the program.